What are the different Recovery Models available in Sql Server
A recovery model is a database configuration option that determines the type of backup that one could perform, and provides the ability to restore the data or recover it from a failure.
The recovery model decides how the transaction log of a database should be maintained and protects the data changes in a specific sequence, which may later be used for a database restore operation.
Types of recovery models
All SQL Server database backup, restore, and recovery operations are based on one of three available recovery models:
- SIMPLE
- FULL
- BULK_Logged
SIMPLE
The SIMPLE recovery model is the simplest among the available models. It supports full, differential, and file level backups. Transaction log backups are not supported. The log space is reused whenever the SQL Server background process checkpoint operation occurs. The inactive portion of the log file is removed and is made available for reuse.
Point-in-time and page restore are not supported, only the restoration of the secondary read-only file is supported.
Reasons to choose the simple database recovery model
- Most suited for Development and Test databases
- Simple reporting or application database, where data loss is acceptable
- The point-of-failure recovery is exclusively for full and differential backups
- No administrative overhead
It supports:
- Full backup
- Differential backup
- Copy-Only backup
- File backup
- Partial backup
FULL
In this recovery model, all the transactions (DDL (Data Definition Language) + DML (Data Manipulation Language)) are fully recorded in the transaction log file. The log sequence is unbroken and is preserved for the databases restore operations. Unlike the Simple recovery model, the transaction log file is not auto-truncated during CHECKPOINT operations.
All restore operations are supported, including point-in-time restore, page restore and file restore.
Reasons to choose the full database recovery model:
- Supporting mission critical applications
- Design High Availability solutions
- To facilitate the recovery of all the data with zero or minimal data loss
- If the database designed to have multiple filegroups, and you want to perform a piecemeal restore of read/write secondary filegroups and, optionally, read-only filegroups.
- Allow arbitrary point-in-time restoration
- Restore individual pages
- Incur high administration overhead
It supports all type of following backups
- Full backup
- Differential backup
- Transaction log backup
- Copy-Only backup
- File and/or file-group backup
- Partial backup
BULK_LOGGED
It’s a special purpose database configuration option and it works similar to FULL recovery model except that certain bulk operations can be minimally logged. The transaction log file uses a technique known as minimal logging for bulk operations. The catch is that it’s not possible to restore specific point-in-time data.
Reasons to choose the bulk logged recovery model:
- Use minimal logging technique to prevent log file growth
- If the database is subjected to periodic bulk operations
It supports all types of backups:
- Full backup
- Differential backup
- Transaction log backup
- Copy-Only backup
- File and/or file-group backup
- Partial backup
Transaction log internals
It’s worth taking the time to understand the internals of the SQL Server transaction log.
- Whenever there is a transaction (DDL and DML) the details of every operation is logged in the transaction log file
- The transaction log backup ensures transactional durability and data consistency using a mechanism known as WAL (Write-Ahead-Logging). The transactions that occur on the database first get registered into the transaction log file and then the data is written to the disk. This facilitates the SQL Server to rollback or roll-forward every step of the recovery process
- Enables point-in-time restore of databases
- SQL Server always writes to the transaction log file sequentially. It’s cyclic in nature. The transaction log file is further divided into log blocks which are logically mapped using VLF’s (Virtual Log Files)
- The log records in the blocks that are no longer needed are deemed as “inactive,” and this portion of the log blocks can be truncated, i.e., the inactive segments of the log blocks are overwritten by new transactions. These segments or portion of the log file are known as virtual log files (VLFs)
- Any inactive VLF can be truncated, although the point at which this truncation can occur depends on the recovery model of the database
- In the SIMPLE recovery model, truncation can take place immediately upon the occurrence of a CHECKPOINT operation. Pages in the data cache are flushed to the disk, having first “hardened” the changes to the log file. The space in any VLFs that becomes inactive as a result, and is made available for reuse
- A database may have multiple log files but it’s mandatory to have at least one. It will only ever write to one log file at a time, and having more than one files will not boost write-throughput or speed. In fact, having more multiple files could result in performance degradation, if each file is not correctly sized or differs in size. Any mismatch leads to longer duration of recovery of the database
- For business-critical databases, it is recommended to initiate full database backups, followed by a series of frequent transaction log backups, followed by another full backup, and so on. As part of the database restore operation, we can restore the most recent full backup (plus differentials, if taken), followed by the chain of available log file backups, up to the one covering the point in time to which we wish to restore the database
Recovery Model Overview
Simple
- Description
- No transaction log backups.
- In the Simple Recovery Model, the transaction log is automatically purged and the file size is kept intact. Because of this, you can’t make log backups in this case.
- Supports only full and bulk_logged backup operations.
- The unsupported features of in simple recovery model are: Log shipping, AlwaysOn or Mirroring and Point-in-time restore
- Data loss
- Yes; we cannot restore the database to an arbitrary point in time. This means, in the event of a failure, it is only possible to restore database as current as the last full or differential backup, and data loss is a real possibility
- Point-in-time restore
- No
Full
- Description
- Supports transaction log backups.
- No work is lost due to a lost or damaged data file. The Full database recovery model completely records every transaction that occurs on the database.
- One could arbitrarily choose a point in time for database restore.
- This is possible by first restoring a full backup, most recent differential then replaying the changes recorded in the transaction log. If a differential backup doesn’t exist, then the series of t-logs are applied.
- Supports Point-in-time data recovery.
- If the database uses the full recovery model, the transaction log would grow infinitely, and that will be a problem. So, we need to make sure that we take transaction log backups on a regular basis.
- Data loss
- Minimal or zero data loss.
- Point-in-time restore
- This setup enables more options.
- Point-in-time recovery.
Bulk logged
- Description
- This model is similar to the Full Recovery Model, in that a transaction log is kept, but certain transactions such as bulk loading operations are minimally logged, although it logs other transaction. This makes the bulk data imports perform quicker and keeps the file size of the transaction log down, but does not support the point in time recovery of the data.
- This can help increase performance bulk load operations.
- Reduces log space usage by using minimal logging for most bulk operations.
- Data loss
- If you run transactions under the bulk-logged recovery model that might require a transaction log restore, these transactions could be exposed to data loss.
- Point-in-time restore
- Point-in-time recovery is not possible with bulk-logged model
- It is possible only if the following conditions are satisfied:
Users are currently not allowed in the database.
If you’re able to re-running the bulk processes.
Switching recovery models
Full and bulk-logged
- Initiate a log backup
- Perform bulk operations, immediately switch back the database to full recovery model
- Initiate transaction log backup
Simple to FULL or Differential
- Initiate a full (or differential, if full is already available) database backup
- Schedule t-log backups
FULL or BULK_Logged to Simple
- Disable the transaction log backup job
- Ensure that there is a job to take full backup
View or change the database recovery model using the following options:
- Using SSMS
- T-SQL
- PowerShell
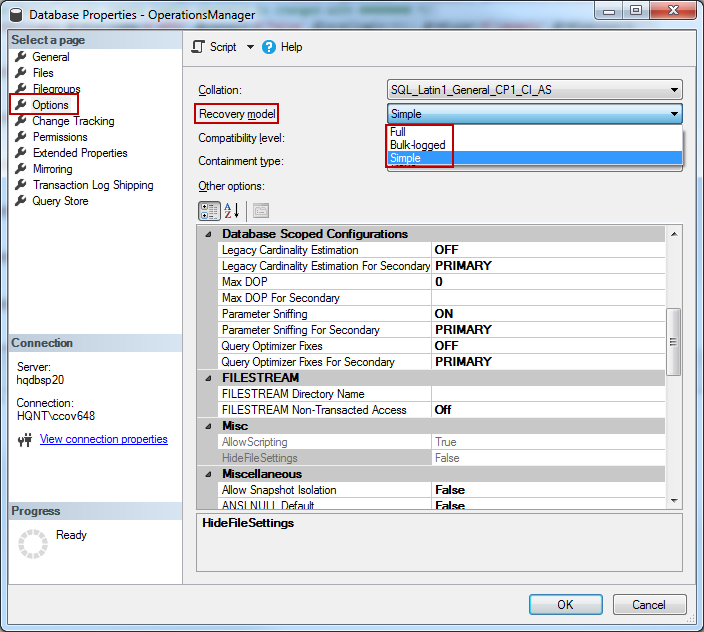
Using SSMS
- Connect to the SQL instance in the Object Explorer, expand Databases, select the desired database
- Right-click the selected database, go to Properties
- In the database properties window, choose Options
- The Recovery model list box highlights the current recovery model
- To change the recovery model, select the desired recovery model: Full, Bulk-logged, or Simple from the drop-down list
Using Transact-SQL
- Connect to the Database Engine
- Open a New Query window
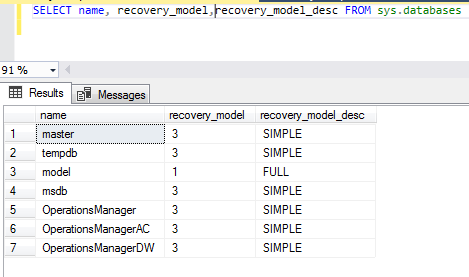
- Query the sys.databases system catalog to view the recovery model of the databases
1 2 | SELECT name, recovery_model,recovery_model_desc FROM sys.databases GO |
To change the recovery model, execute the alter database statement with set recovery option. For example, the recovery model of the database is set to SIMPLE using.
1 2 3 4 | USE master GO ALTER DATABASE MODEL SET RECOVERY SIMPLE ; SELECT name, recovery_model,recovery_model_desc FROM sys.databases where name='model' |
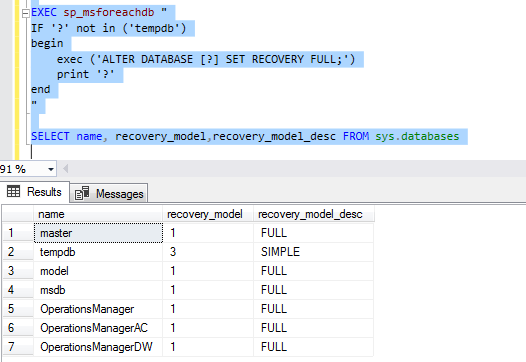
How to change the recovery model of entire databases of SQL Server instance?
The undocumented stored procedure, sp sp_msforeachdb, is used to iterate through every database and execute the alter database command.
1 2 3 4 5 6 7 8 9 | EXEC sp_msforeachdb " IF '?' not in ('tempdb') begin exec ('ALTER DATABASE [?] SET RECOVERY FULL;') print '?' end " SELECT name, recovery_model,recovery_model_desc FROM sys.databases |
How to check the recovery model of entire databases in an SQL environment?
In most production servers, the database recovery model is set to FULL. There may be a chance, though, that the recovery model is switched for some reason. Let’s identify all the production databases where the recovery model is SIMPLE. In order to do that, dynamic T-SQL, sqlcmd and Windows scripting are used. The T-SQL query is run against all the servers using SQL Server agent scheduled job to get the desired output.
Input file – the list contains the names of the production server
- Define the SQL query in a file123USE MASTERGOSELECT name, recovery_model,recovery_model_desc FROM sys.databases where database_id>4 and recovery_model=3

- Prepare the dynamic T-SQL and run the query using SSMS1MASTER..XP_CMDSHELL 'for /f %h in (\\share\hq\inputserver.txt) do sqlcmd -S %h -i \\Share\hq\SQLRecoveryModelCheck.sql -E'
Validate the output
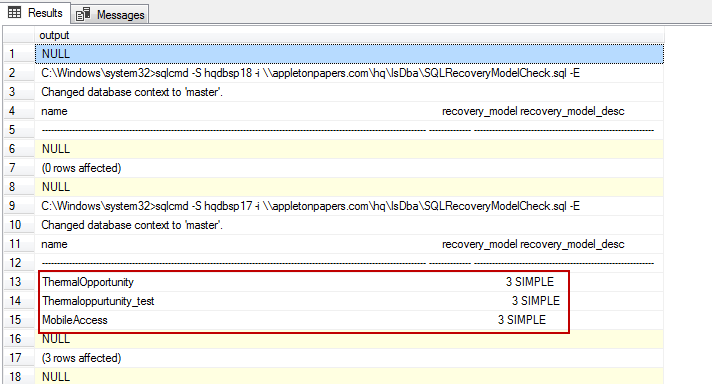
- Filename – the file contains a list of servers
- Recovery_model_desc – this is a recovery model search pattern; for example, “simple”, “full”, “bulk_logged”
- Database_Flag – this flag excludes system databases
Using PowerShell
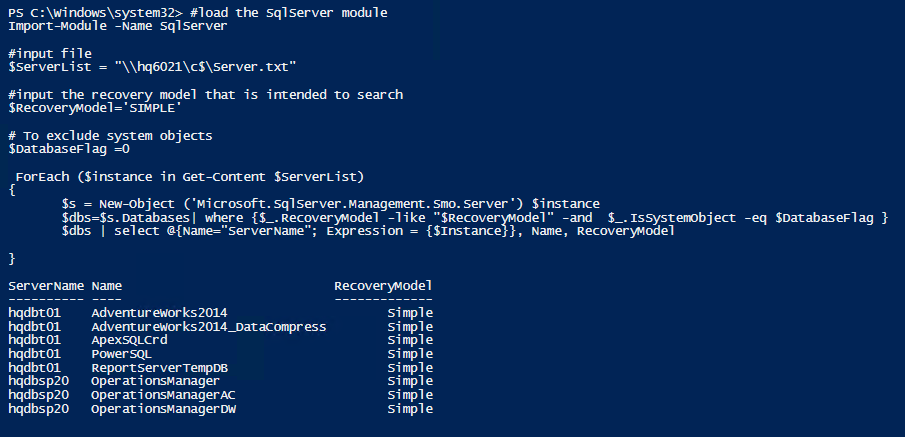
The function Get-RecoveryModel has three input parameters
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #load the SqlServer module Import-Module -Name SqlServer #input file $ServerList = "\\hq6021\c$\Server.txt" #input the recovery model that is intended to search $RecoveryModel='SIMPLE' # To exclude system objects $DatabaseFlag =0 ForEach ($instance in Get-Content $ServerList) { $s = New-Object ('Microsoft.SqlServer.Management.Smo.Server') $instance $dbs=$s.Databases| where {$_.RecoveryModel -like "$RecoveryModel" -and $_.IsSystemObject -eq $DatabaseFlag } $dbs | select @{Name="ServerName"; Expression = {$Instance}}, Name, RecoveryModel } |
Post a Comment
0 Comments