What is Column Store Index?
Ref: https://www.red-gate.com/simple-talk/databases/sql-server/t-sql-programming-sql-…
How to Allow multiple NULL values in Unique Column?
Unique fields in SQL Server are created using unique constraints or unique indexes, …

What is the difference between Unique Constraint and Unique Index?
Before getting started, let me briefly describe SQL Server unique indexes vs. uniq…
What is a Covering Query or Covering Index?
What is a covering query? If all the columns that you have requested in the SELECT …
Differences between Clustered Index and NonClustered Index
The differences between Clustered Index and NonClustered Index is one of the most com…

Describe the structure of a SQL Server Index that provides faster access to the table’s data?
A SQL Server index is created using the shape of B-Tree structure, that is made up o…

What are Indexes in SQl Server? What is their advantages and disadvantages?
Why indexes? Indexes are used by queries to find data from tables quickly. Indexes a…
How to Allow multiple NULL values in Unique Column?
(
id INT IDENTITY(1, 1),
value VARCHAR(30) NULL UNIQUE
)
INSERT INTO testunique
VALUES (‘value1’)
VALUES (NULL)
INSERT INTO testunique
VALUES (‘value1’)
VALUES (NULL)
(
id INT IDENTITY(1, 1),
value VARCHAR(30) NULL
)
CREATE UNIQUE INDEX indunique
ON testunique(value)
WHERE value IS NOT NULL
INSERT INTO testunique
VALUES (‘value1’)
VALUES (NULL)
INSERT INTO testunique
VALUES (‘value1’)
— of the index, therefore duplicate values are accepted
INSERT INTO testunique
VALUES (NULL)
What is the difference between Unique Constraint and Unique Index?
- A unique index ensures that the values in the index key columns are unique.
- A unique constraint also guarantees that no duplicate values can be inserted into the column(s) on which the constraint is created. When a unique constraint is created a corresponding unique index is automatically created on the column(s).
USE master GO -- Creating database CREATE DATABASE TestDB GO USE TestDB GO -- Creating table CREATE TABLE TestTable ( ID INT, Value INT, NewValue INT, CONSTRAINT PK_TestTable_ID PRIMARY KEY (ID) ) GO
Creating a SQL Server Unique Index or Unique Constraint
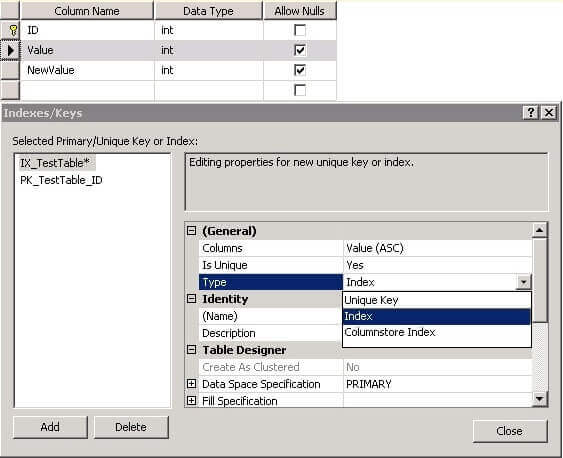
USE TestDB GO -- Creating unique index CREATE UNIQUE INDEX UIX_TestTable_Value ON TestTable(Value) GO --Creating unique constraint ALTER TABLE TestTable ADD CONSTRAINT UC_TestTable_NewValue UNIQUE (NewValue) GO
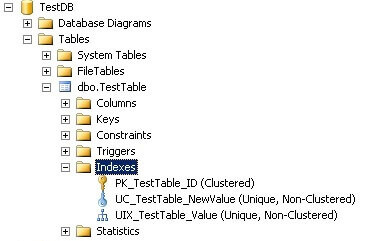
USE TestDB GO EXEC sys.sp_helpindex @objname = N'TestTable' GO

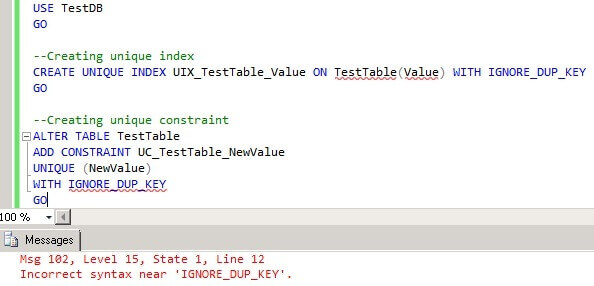
USE TestDB GO -- Creating unique index CREATE UNIQUE INDEX UIX_TestTable_Value ON TestTable(Value) WITH IGNORE_DUP_KEY GO -- Creating unique constraint ALTER TABLE TestTable ADD CONSTRAINT UC_TestTable_NewValue UNIQUE (NewValue) WITH IGNORE_DUP_KEY GO
Dropping a SQL Server Unique Index or Unique Constraint
USE TestDB GO -- Dropping indexes DROP INDEX TestTable.UIX_TestTable_Value GO DROP INDEX TestTable.UC_TestTable_NewValue GO

USE TestDB GO --Dropping constraint ALTER TABLE TestTable DROP CONSTRAINT UC_TestTable_NewValue GO
Disable a SQL Server Unique Constraint
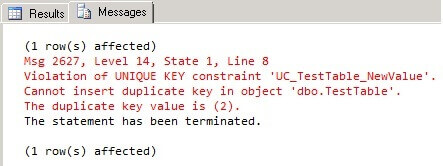
USE TestDB GO -- Creating unique constraint ALTER TABLE TestTable ADD CONSTRAINT UC_TestTable_NewValue UNIQUE (NewValue) GO -- Disabling all constraints ALTER TABLE TestTable NOCHECK CONSTRAINT ALL GO
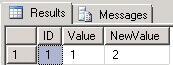
USE TestDB GO -- Inserting duplicate data INSERT INTO TestTable(ID, Value, NewValue) VALUES(1, 1, 2) GO INSERT INTO TestTable(ID, Value, NewValue) VALUES(2, 2, 2) GO SELECT * FROM TestTable GO
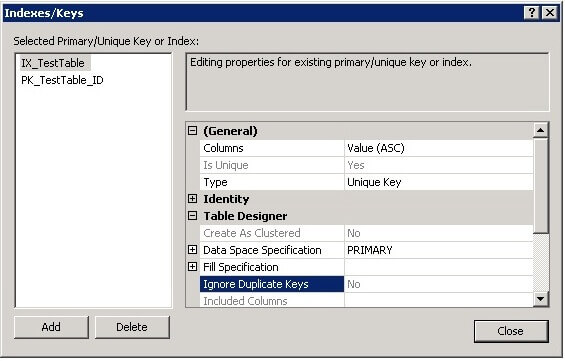
Unique Constraint: You cannot add filter in Unique Constraint.
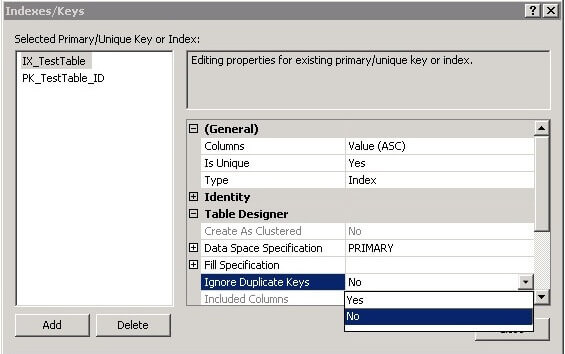
Unique Index: You can add filter in Unique Index:
Conclusion
Generally there is no functional difference between a unique index and a unique constraint. The latter is also listed as a constraint, however this is only a method to emphasize the purpose of the index. There is no difference for the query optimizer whether the index is created as a unique index or a unique constraint, therefore there is no performance difference. However there are some differences for creation where some index creation options are not available for unique constraints.Ref : https://www.dbrnd.com/2017/07/sql-server-interview-what-is-the-difference-between-unique-constraint-and-unique-index/
Ref: https://www.mssqltips.com/sqlservertip/4270/difference-between-sql-server-unique-indexes-and-unique-constraints/
What is a Covering Query or Covering Index?
What is a covering query?
If all the columns that you have requested in the SELECT clause of query, are present in the index, then there is no need to lookup in the table again. The requested columns data can simply be returned from the index.A clustered index, always covers a query, since it contains all of the data in a table. A composite index is an index on two or more columns. Both clustered and nonclustered indexes can be composite indexes. To a certain extent, a composite index, can cover a query.
Differences between Clustered Index and NonClustered Index
Clustered Index
- A Table can have ONLY 1 Clustered Index.
- A Clustered Index always has Index Id of 0.
- A Primary Key constraint creates a Clustered Index by default.
- A Primary Key constraint can also be enforced by Nonclustered Index, You can specify the index type while creating Primary Key.
- If the table does not have Clustered Index it is referred to as a "Heap".
- The leaf node of a Clustered Index contains data pages of the table on which it is created.
- Clustered Index enforces a logical order on the rows. Rows are ordered based on Clustering Key.
- Faster to read than non clustered as data is physically stored in index order.
- Prior to SQL Server 2008 only 249 Nonclustered Indexes can be created. With SQL Server 2008 and above 999 Nonclustered Indexes can be created.
- Nonclustered Indexes have Index Id > 0.
- A Unique Key constraint created a Nonclustered Index by default.
- A Unique Key constraint can also be enforced by Clustered Index, You can specify the index type while creating Unique Key
- Nonclustered Index does not order actual data, It only orders columns present in the Nonclustered Index based on Index Key specified at the time of creation of Nonclustered Index.
- A table may not have any Nonclustered Indexes.
- The leaf nodes of a Nonclustered Index consists of Index pages which contain Clustering Key or RID to locate Data Row.
- When Clustered Index is not present leaf node points to Physical Location of the row this is referred to as RID. When a Clustered Index is present this points to Clustering Key (Key column on which Clustered Index is created).
- Quicker for insert and update operations than a clustered index.
| Clustered Index | Non- Clustered Index |
| The Clustered Indexes are indexes which will sort the data physically | Non- Clustered indexes does not sort the data physically. These are logical indexes. |
| Only one clustered index created for one column | User can create up to 999 non- clustered indexes |
| These indexes are faster to read than non- clustered indexes | Non- clustered indexes are slower in read operation as compare to clustered indexes. |
| The select operations are fast in clustered indexes | Insert and update operations are fast in non-clustered indexes |
| Clustered indexes will only sort the table in specific order so it will not consume the physical space | Non-clustered indexes are physically stored indexes which works in logical way. |
| Clustered index contains data at the leaf node | Non- clustered indexes do not contain data at leaf node. |
Describe the structure of a SQL Server Index that provides faster access to the table’s data?
A SQL Server index is created using the shape of B-Tree structure, that is made up of 8K pages, with each page, in that structure, called an index node. The B-Tree structure provides the SQL Server Engine with a fast way to move through the table rows based on index key, that decides to navigate left or right, to retrieve the requested values directly, without scanning all the underlying table rows. You can imagine the potential performance degradation that may occur due to scanning large database table.
The B-Tree structure of the index consists of three main levels:

- the Root Level, the top node that contains a single index page, form which SQL Server starts its data search,
- the Leaf Level, the bottom level of nodes that contains the data pages we are looking for, with the number of leaf pages depends on the amount of data stored in the index,
- and finally the Intermediate Level, one or multiple levels between the root and the leaf levels that holds the index key values and pointers to the next intermediate level pages or the leaf data pages. The number of intermediate levels depends on the amount of data stored in the index.
What are Indexes in SQl Server? What is their advantages and disadvantages?
Why indexes?
Indexes are used by queries to find data from tables quickly. Indexes are created on tables and views. Index on a table or a view, is very similar to an index that we find in a book.If you don't have an index in a book, and I ask you to locate a specific chapter in that book, you will have to look at every page starting from the first page of the book.
On, the other hand, if you have the index, you lookup the page number of the chapter in the index, and then directly go to that page number to locate the chapter.
Obviously, the book index is helping to drastically reduce the time it takes to find the chapter.
In a similar way, Table and View indexes, can help the query to find data quickly.
In fact, the existence of the right indexes, can drastically improve the performance of the query. If there is no index to help the query, then the query engine, checks every row in the table from the beginning to the end. This is called as Table Scan. Table scan is bad for performance.
If we can reduce the I/O required to find the information we want, we can effectively give the bottle a bigger neck.
This reduction will also lead to secondary benefits, such as reduced CPU time, waits, cache use and more.
The goal of an index on a database table then is to reduce I/O.
The following are the different types of indexes in SQL Server
1. Clustered
2. Nonclustered
3. Unique
4. Filtered
5. XML
6. Full Text
7. Spatial
8. Columnstore
9. Index with included columns
10. Index on computed columns
Clustered Index:
A clustered index determines the physical order of data in a table. For this reason, a table can have only one clustered index.
Create tblEmployees table using the script below.
CREATE TABLE [tblEmployee]
(
[Id] int Primary Key,
[Name] nvarchar(50),
[Salary] int,
[Gender] nvarchar(10),
[City] nvarchar(50)
)
Note that Id column is marked as primary key. Primary key, constraint create clustered indexes automatically if no clustered index already exists on the table and a nonclustered index is not specified when you create the PRIMARY KEY constraint.
To confirm this, execute sp_helpindex tblEmployee, which will show a unique clustered index created on the Id column.
Now execute the following insert queries. Note that, the values for Id column are not in a sequential order.
Insert into tblEmployee Values(3,'John',4500,'Male','New York')
Insert into tblEmployee Values(1,'Sam',2500,'Male','London')
Insert into tblEmployee Values(4,'Sara',5500,'Female','Tokyo')
Insert into tblEmployee Values(5,'Todd',3100,'Male','Toronto')
Insert into tblEmployee Values(2,'Pam',6500,'Female','Sydney')
Execute the following SELECT query
Select * from tblEmployee
Inspite, of inserting the rows in a random order, when we execute the select query we can see that all the rows in the table are arranged in an ascending order based on the Id column. This is because a clustered index determines the physical order of data in a table, and we have got a clustered index on the Id column.
Because of the fact that, a clustered index dictates the physical storage order of the data in a table, a table can contain only one clustered index. If you take the example of tblEmployee table, the data is already arranged by the Id column, and if we try to create another clustered index on the Name column, the data needs to be rearranged based on the NAME column, which will affect the ordering of rows that's already done based on the ID column.
For this reason, SQL server doesn't allow us to create more than one clustered index per table. The following SQL script, raises an error stating 'Cannot create more than one clustered index on table 'tblEmployee'. Drop the existing clustered index PK__tblEmplo__3214EC0706CD04F7 before creating another.'
Create Clustered Index IX_tblEmployee_Name
ON tblEmployee(Name)
A clustered index is analogous to a telephone directory, where the data is arranged by the last name. We just learnt that, a table can have only one clustered index. However, the index can contain multiple columns (a composite index), like the way a telephone directory is organized by last name and first name.
Let's now create a clustered index on 2 columns. To do this we first have to drop the existing clustered index on the Id column.
Drop index tblEmployee.PK__tblEmplo__3214EC070A9D95DB
When you execute this query, you get an error message stating 'An explicit DROP INDEX is not allowed on index 'tblEmployee.PK__tblEmplo__3214EC070A9D95DB'. It is being used for PRIMARY KEY constraint enforcement.' We will talk about the role of unique index in the next session. To successfully delete the clustered index, right click on the index in the Object explorer window and select DELETE.
Now, execute the following CREATE INDEX query, to create a composite clustered Index on the Gender and Salary columns.
Create Clustered Index IX_tblEmployee_Gender_Salary
ON tblEmployee(Gender DESC, Salary ASC)
Now, if you issue a select query against this table you should see the data physically arranged, FIRST by Gender in descending order and then by Salary in ascending order. The result is shown below.
Non Clustered Index:
A nonclustered index is analogous to an index in a textbook. The data is stored in one place, the index in another place. The index will have pointers to the storage location of the data. Since, the nonclustered index is stored separately from the actual data, a table can have more than one non clustered index, just like how a book can have an index by Chapters at the beginning and another index by common terms at the end.
In the index itself, the data is stored in an ascending or descending order of the index key, which doesn't in any way influence the storage of data in the table.
Create NonClustered Index IX_tblEmployee_Name
ON tblEmployee(Name)
Difference between Clustered and NonClustered Index:
1. Only one clustered index per table, where as you can have more than one non clustered index
2. Clustered index is faster than a non clustered index, because, the non-clustered index has to refer back to the table, if the selected column is not present in the index.
3. Clustered index determines the storage order of rows in the table, and hence doesn't require additional disk space, but where as a Non Clustered index is stored seperately from the table, additional storage space is required.
Create the Employee table using the script below
CREATE TABLE [tblEmployee]
(
[Id] int Primary Key,
[FirstName] nvarchar(50),
[LastName] nvarchar(50),
[Salary] int,
[Gender] nvarchar(10),
[City] nvarchar(50)
)
Since, we have marked Id column, as the Primary key for this table, a UNIQUE CLUSTERED INDEX gets created on the Id column, with Id as the index key.
We can verify this by executing the sp_helpindex system stored procedure as shown below.
Execute sp_helpindex tblEmployee
Output:

Since, we now have a UNIQUE CLUSTERED INDEX on the Id column, any attempt to duplicate the key values, will throw an error stating 'Violation of PRIMARY KEY constraint 'PK__tblEmplo__3214EC07236943A5'. Cannot insert duplicate key in object dbo.tblEmployee'
Example: The following insert queries will fail
Insert into tblEmployee Values(1,'Mike', 'Sandoz',4500,'Male','New York')
Insert into tblEmployee Values(1,'John', 'Menco',2500,'Male','London')
Drop index tblEmployee.PK__tblEmplo__3214EC07236943A5
So this error message proves that, SQL server internally, uses the UNIQUE index to enforce the uniqueness of values and primary key.
Expand keys folder in the object explorer window, and you can see a primary key constraint. Now, expand the indexes folder and you should see a unique clustered index. In the object explorer it just shows the 'CLUSTERED' word. To, confirm, this is infact an UNIQUE index, right click and select properties. The properties window, shows the UNIQUE checkbox being selected.

SQL Server allows us to delete this UNIQUE CLUSTERED INDEX from the object explorer. so, Right click on the index, and select DELETE and finally, click OK. Along with the UNIQUE index, the primary key constraint is also deleted.
Now, let's try to insert duplicate values for the ID column. The rows should be accepted, without any primary key violation error.
Insert into tblEmployee Values(1,'John', 'Menco',2500,'Male','London')
So, the UNIQUE index is used to enforce the uniqueness of values and primary key constraint.
UNIQUENESS is a property of an Index, and both CLUSTERED and NON-CLUSTERED indexes can be UNIQUE.
Creating a UNIQUE NON CLUSTERED index on the FirstName and LastName columns.
Create Unique NonClustered Index UIX_tblEmployee_FirstName_LastName
On tblEmployee(FirstName, LastName)
This unique non clustered index, ensures that no 2 entires in the index has the same first and last names. In Part 9, of this video series, we have learnt that, a Unique Constraint, can be used to enforce the uniqueness of values, across one or more columns. There are no major differences between a unique constraint and a unique index.
In fact, when you add a unique constraint, a unique index gets created behind the scenes. To prove this, let's add a unique constraint on the city column of the tblEmployee table.
ALTER TABLE tblEmployee
ADD CONSTRAINT UQ_tblEmployee_City
UNIQUE NONCLUSTERED (City)
At this point, we expect a unique constraint to be created. Refresh and Expand the constraints folder in the object explorer window. The constraint is not present in this folder. Now, refresh and expand the 'indexes' folder. In the indexes folder, you will see a UNIQUE NONCLUSTERED index with name UQ_tblEmployee_City.
Also, executing EXECUTE SP_HELPCONSTRAINT tblEmployee, lists the constraint as a UNIQUE NONCLUSTERED index.

So creating a UNIQUE constraint, actually creates a UNIQUE index. So a UNIQUE index can be created explicitly, using CREATE INDEX statement or indirectly using a UNIQUE constraint. So, when should you be creating a Unique constraint over a unique index.To make our intentions clear, create a unique constraint, when data integrity is the objective. This makes the objective of the index very clear. In either cases, data is validated in the same manner, and the query optimizer does not differentiate between a unique index created by a unique constraint or manually created.
Note:
1. By default, a PRIMARY KEY constraint, creates a unique clustered index, where as a UNIQUE constraint creates a unique nonclustered index. These defaults can be changed if you wish to.
2. A UNIQUE constraint or a UNIQUE index cannot be created on an existing table, if the table contains duplicate values in the key columns. Obviously, to solve this,remove the key columns from the index definition or delete or update the duplicate values.
CREATE UNIQUE INDEX IX_tblEmployee_City
ON tblEmployee(City)
WITH IGNORE_DUP_KEY
https://www.sqlshack.com/top-10-questions-answers-sql-server-indexes/